The investor's approach to ML projects

Photo by Keenan Constance on Unsplash
How do you set Machine Learning projects for success?
There are many opportunities to create value with ML: increasing productivity, avoiding undesirable events, automating repetitive tasks... But there are also many sources of cost and uncertainty. ML projects can feel like games of poker: you need to pay to see if you've got a winning idea, and you should avoid going all-in without strong odds in your favor!
How can you figure out your odds, maximize chances of success, and minimize costs? By thinking like an investor! Here are 9 steps:
- Write the plan
- Conduct customer/user studies
- Set up Proof of Value with simulations and AutoML
- Invest in data to increase performance
- Shadow-deploy a Minimum Viable Product
- Update model with new data
- Canary-test and monitor
- Invest in larger-scale deployment
- Increase value / generate new value
1. Write the plan
When starting a new business, you’d use the business model canvas. For ML projects, use the ML Canvas. It helps connect a value proposition to a prediction problem, identify bottlenecks, anticipate costs, and define the desired performance level.
Here are some questions you'll need to answer:
- Which value are you proposing, for which end-user?
- Which prediction problem are you targeting?
- How are you turning predictions into the proposed value? (Tip: ask yourself "what would I do if I already had a perfect model?")
- How are you changing the end-user workflow?
- How will you monitor the impact, quantify, and prove that value is created?
The MLC helps formalize your plan, which you can use to better communicate with others, and convince them to join your efforts. Starting with the MLC is recommended practice at AWS. There are a few other frameworks with similar names, but what's unique with this one is that it helps anticipate running costs of the ML system you set out to build. For instance, you'll have to think about the volume of models and predictions to create, and this will determine infrastructure costs.

2. Conduct customer/user studies
Wouldn't it be great if you could make sure that end-users of your ML system will be able to use it — and that they'll want to — before you start building? For this, you can use mockups and run "wizard-of-oz" experiments, where you fake the ML system. It's been recommended practice at Google for years.
Early UX research can also result in a better plan that factors in feedback loops (those could hurt in the long term) and new data collection opportunities.
3. Set up Proof of Value with simulations and AutoML

If ML was a car, AutoML would be Tesla’s Autopilot! Actually, H2o.ai’s solution is even called Driverless AI…
Before investing too much time/money/efforts, you'll want to create a baseline model with minimal costs, and in the quickest way possible. This means small data (e.g. 50 examples of each class, for a classification problem), automated ML, and no data scientist!
You will then proceed to proving that this baseline model can create value, by running it through a simulation (aka “offline evaluation”). The idea is to see how much value it would create, by making correct predictions on a "test" dataset. For this, you'll be using cost/gain values for the different types of incorrect/correct predictions.
One way to get a test dataset is to split your existing data into training and test sets, but there's a risk of "data leakage". The most secure option is to collect some more data, and to use it as test.
If you've reached your desired performance value, great! Go to step 5.
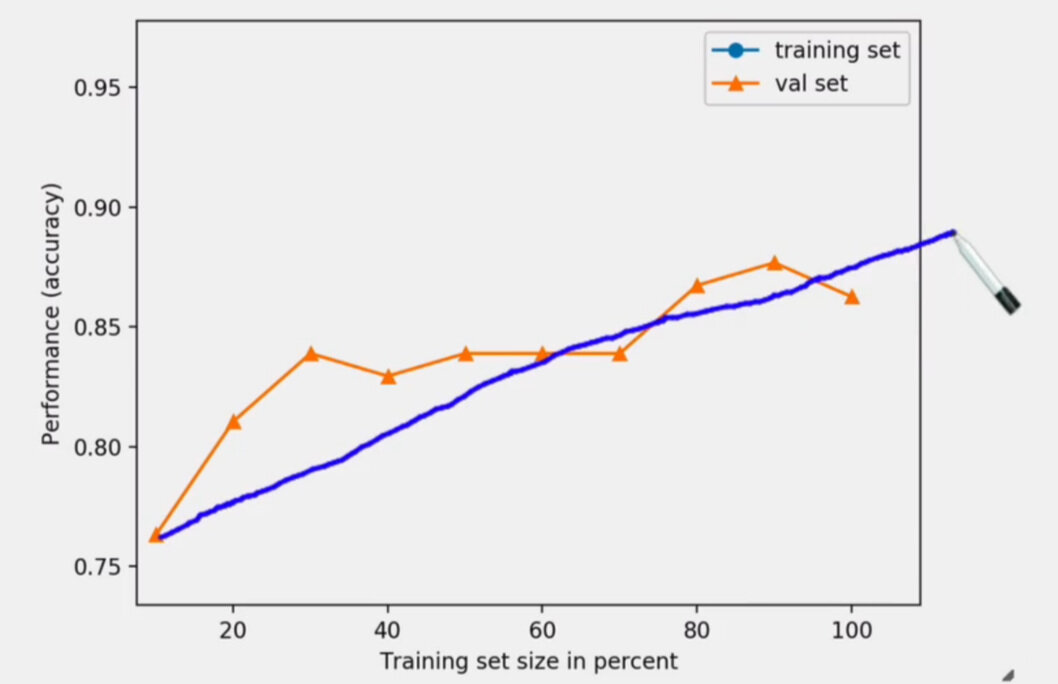
Learning curve extrapolation
4. Invest in data to increase performance
Where should you invest, to increase performance? Common ideas are to: a) tune the ML algorithm, b) collect more data, c) improve data preparation.
One of the highlights of my survey results on what managers should know about ML was Sébastien Arnaud's "invest in data, and activities around it: cleaning, analysis, processing pipeline, annotation, labelling, training/test set, validation." Indeed, the most impactful improvements to your ML system will be coming from data collection and preparation. This means you should forget about a).
To choose between b) and c) you need to plot a learning curve. This consists in running the previous simulation again but with subsets of the training data that go from 10% to 100% in size (see illustration). You would look at how performance increases with the amount of training data that's available. Also consider how much time/money it took to acquire this training set (getting unbiased data can come at a cost, e.g. randomly approving transactions or loan applications). What happens if you extrapolate to more data?
How do you generate ideas to improve data preparation? The key is to inspect individual predictions among top errors, top predictions, and most uncertain ones. Prioritize ideas by grouping errors in different types, and counting occurrences of each type. Inspecting predictions also helps determine if you can trust the model: look at prediction explanations and check that they make sense.
Go through the implementation/inspection loop a few times, until performance is higher than the desired value. If you can't get there quickly enough, consider changing parameters of your prediction problem (e.g. reducing the time horizon).

5. Shadow-deploy a Minimum Viable Product
"Shadow-deployment" is the same as real deployment in production, except you don’t actually use predictions but you just log them. This allows to check whether model performance on production inputs is similar to what it was on test inputs. You'll also want to monitor performance through time, to see how fast it decreases, and thus to inform model refresh rate (i.e. updating with fresher data).
In the context of ML, a Minimum Viable Product (MVP) isn't just a model, but it's a system that's made of several components — read more in this post and see how these components are interconnected in the diagram above. You should use an ML platform to get (and configure) a production-ready model builder and a server, and you should start with manual orchestration (this doesn't need to be a software component at first).
Finally, use shadow-deployment to check all running costs (ML platform / tools / infrastructure / compute), and see if there are any additional ones you hadn’t anticipated, when going from a lab environment to production.
6. Update model with new data
As hinted above, you can expect performance to go down with time. This is because the dataset used to build your model becomes less and less representative of the reality, as time goes by. You'll need to periodically retrain your model with fresher data.
In the previous section, I advised to start with manual orchestration, which means manual (re)training and deployment. This should be fine in most cases, but you should test your ability to do this in a timely manner and without errors. This will also be an opportunity to collect new inputs and outputs and thus to confirm the cost of data collection.
7. Canary-test and monitor
I already mentioned monitoring in step 5, but this was about the model's performance. You'll also want to monitor the impact of your ML system, and make sure that you're system is creating value. But for this, you need to act on predictions and to integrate them into your end-users' app / workflow. You can start doing this for just a small subset of them (the "canary test"), to minimize the risk of "breaking" things with your new ML system.
8. Invest in larger scale deployment
Larger scale means increasing the subset of end-users who will be exposed to the new ML system / product. This means more predictions, higher running costs, changing the workflow of more people...
These costs have to be paid before getting gains, but you’ve proved that your MVP creates value, so eventually it will pay off!
9. Increase value or generate new value?
If you're looking to invest more in ML, you have two options: 1) improve the current system and thus increase the value it creates, or 2) generate new value with a new ML use case.
Increase value
Now's the right time to hire data scientists to tune modelling algorithms, or ML engineers to automate orchestration!
- Modelling improvements will result in higher performance, thus more value creation.
- The idea with automation is to spend less time maintaining the system in production. You'll be setting up alerts (based on live performance, data drift detection...), triggers, and actions (train model, evaluate, deploy).
Generate new value
Targeting a new ML use case might provide a higher Return On Investment, if you make your ML assets reusable: reusing your previous data acquisition and preparation pipelines for other ML use cases involving the same input objects will greatly reduce the cost of deploying an MVP. This is something that Uber does with their "feature store", where you can reuse feature representations of drivers across use cases, for instance.

10. (Bonus) Invest in ML education
In the end, Machine Learning is software. But it's a very different paradigm than "regular" software. If you want to be smart about how you allocate ressources to execute ML projects successfully, you need to adopt the right mindset and you need the right amount of practical knowledge (but don't trouble yourself with books on ML algorithms and fancy Python libraries).
I created a hands-on course that covers the above 9 steps in more detail. It's targeted at leaders, innovators, managers, entrepreneurs, domain experts, and consultants. It teaches the skills to lead ML projects more effectively, and to build ML systems that create value: it's called Own Machine Learning!
As Warren Buffet said, “there’s one investment that supersedes all others: invest in yourself.” Here, you'll need to invest 15 hours of your time to watch the course's videos, and about the same to do the exercices. This is the equivalent of 4 days of work (obviously, I invested way more time to acquire that same knowledge I'm passing on 😉). If you're a consultant, this is time that you won't be billing. But it will pay off by making you better at selling and leading ML projects, and faster at executing them successfully!

“I can build my own ML projects, and it feels great”